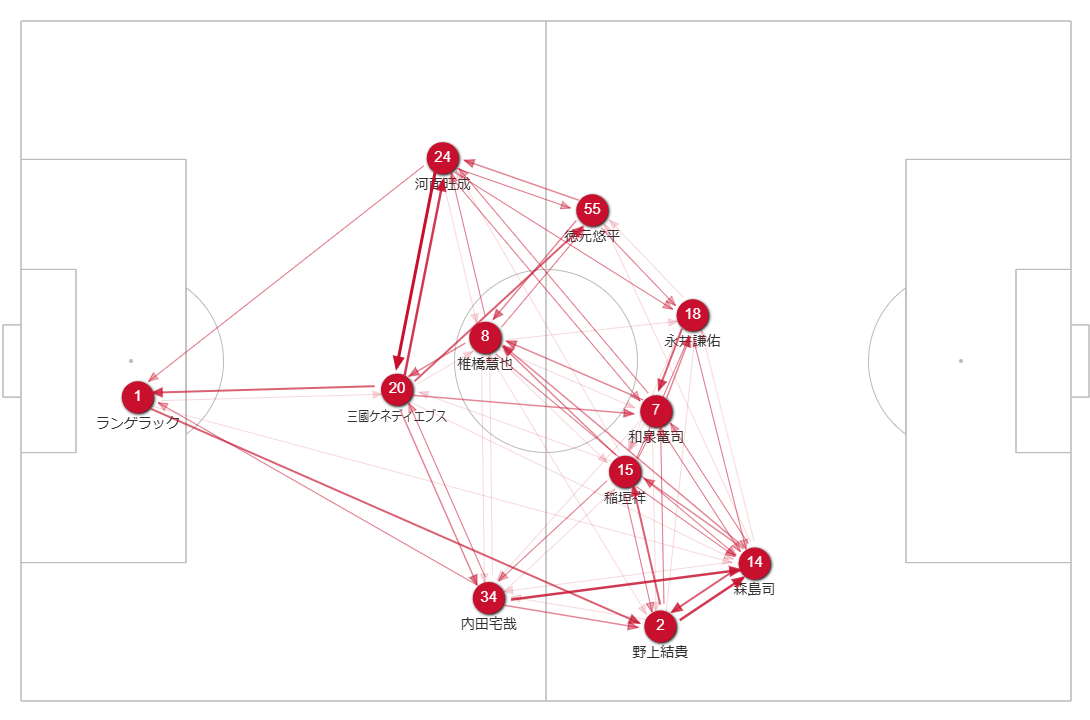
富士ゼロックススーパーカップが終わり、いよいよ2/25から明治安田生命J1リーグが開幕する。
本稿では、データスタジアムが保有する、2016年のJ1リーグ全出場選手の試合ごとのスタッツデータ※401項目を、機械学習手法を駆使して解析、各チームの勝敗予測モデルを作成することによって、2017年のJ1リーグの展望をデータから予測してみる。
※ここでのスタッツデータとは、選手の走行距離やスプリント回数といったトラッキングデータと、インターセプト、パスやシュート、ドリブルの回数といったプレーデータを指す。
サッカーの勝敗予測はどのように行えばよいだろうか。サッカーは、ゴールが対戦相手よりも多いチームが勝利するスポーツだ。サッカーにおけるゴール数は、野球やバスケットボールなど他のスポーツと比較し、一般的に少ない。2016年J1リーグでは805ゴールが生まれたが、1試合における、各チームのゴール数は平均1.3ゴールであった。また、1試合における両チームあわせたゴール数が3ゴール以内だった試合は全体の71.6%となった。
さてこのような滅多に起きない事象は、ポワソン分布と呼ばれる確率分布に従うことが知られている。ポワソン分布とは、いわゆる左右対称の正規分布ではなく、0や1といった小さい値となる確率が大きい確率分布となり、事象の平均値から求められる。

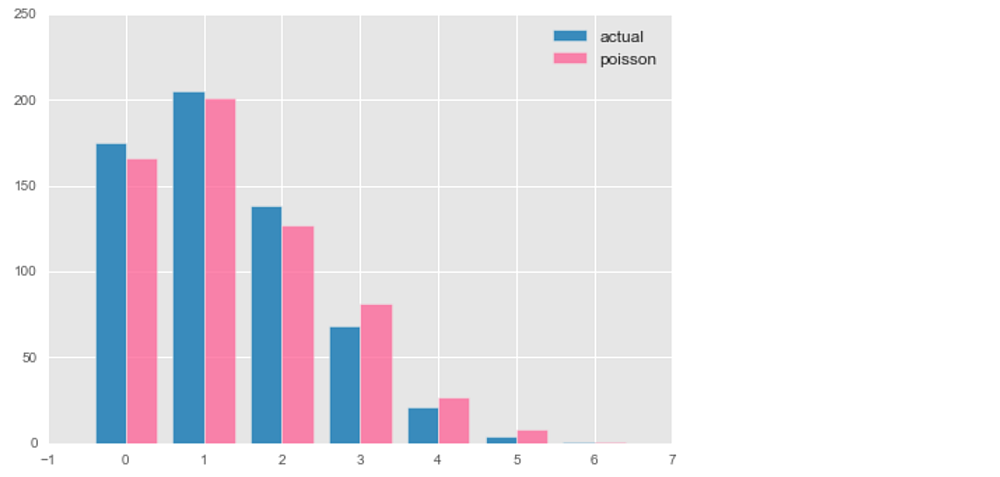
横軸:ゴール数、縦軸:頻度(各ゴールとなった試合数)
たしかにJ1リーグのゴール数の確率分布は、ポワソン分布で近似できそうだ。各チームの1試合平均ゴール数を用いれば、チームごとのゴール数を確率的に予測することができる。たとえば、川崎フロンターレ(1試合平均ゴール数:2.0)と浦和レッズ(1試合平均ゴール数:1.7)におけるポワソン分布に従うゴール数ごとの確率は下記の通りとなる。
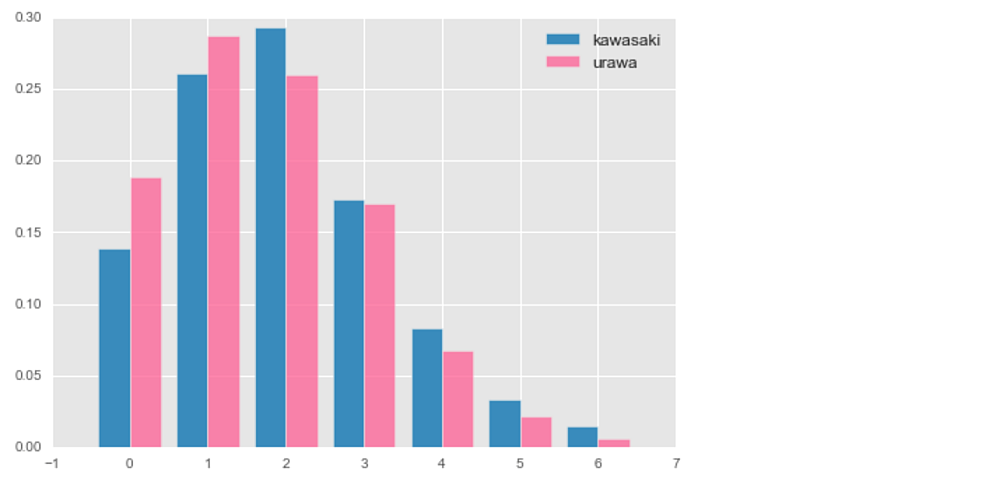
横軸:ゴール数、縦軸:発生確率
青の棒グラフ:川崎フロンターレのゴール数の確率分布
赤の棒グラフ:浦和レッズのゴール数の確率分布
ゴール数が多いチームが勝ちとなるので、両者のゴール数確率を比較することで、勝敗を予測することができる。たとえば、上記のポワソン分布からの勝敗確率は下記の通りとなる。
川崎フロンターレ勝利:43.7%
引き分け:34.7%
浦和レッズ勝利:21.6%
これがもっともシンプルなモデルだが、精度向上のために、いくつかの重要なことを考慮しなければならない。サッカーはゴールが”対戦相手よりも”上回ればよい。すなわち、多くのゴールを目指すのではなく、まずは対戦相手にゴールさせず、少ないゴールで勝利する、堅守をベースにしたチームがある(得失点があるのでゴールが多いことにこしたことはないが)。また、ゴール数は対戦相手によって異なることが予想され、上位チーム、下位チームとの対戦では期待されるゴール数は異なると思われる。
そこで、試合ごとに、自チームおよび対戦相手チームの様々なスタッツデータとゴール数を機械学習し、異なる相手によって異なる平均ゴール数の期待値を予測し、その値を用いてポワソン分布からのゴール数確率分布を比較することが考えられる。
STEP.1: 試合ごとの自チーム・対戦チームのスタッツデータとゴール数の関係を機械学習
STEP.2: STEP.1のモデルを用いて、予想したい自チーム・対戦チーム(のスタッツデータ)から(平均)ゴール数を予測
STEP.3: STEP.2の平均ゴール数からポワソン分布によって、ゴール数を確率的に予測し、両チームで比較、勝敗予測とする。
※STEP.2のゴール数自体を比較して勝敗予測としていないのは、確率としての幅をもたせるため。
※ポワソン分布を、対戦チームごとにもとめるアプローチも考えられるが、スタッツデータを機械学習
することで、選手の移籍などで自チーム・対戦チームのパラメータが変化した際にも対応できるモデル
とした。(今オフは主力選手の移籍はホットトピックである※詳細後述)

Columns


Graphics